Some time ago I published article about my own NAT64 gateway and configuration for it was quite far away from perfect:
It even looks ugly as you need to keep this prefix in mind all the time. IPv6 offers very nice way to announce such prefix from our NAT64 box automatically using RA / Router Advertisement announces.
To make it possible we need to install package:
sudo apt-get install -y radvd
Then we need to create configuration for it in file /etc/radvd.conf :
interface end0 {
MinRtrAdvInterval 3;
MaxRtrAdvInterval 5;
AdvSendAdvert on;
AdvDefaultLifetime 0;
route 64:ff9b::/96 {};
};
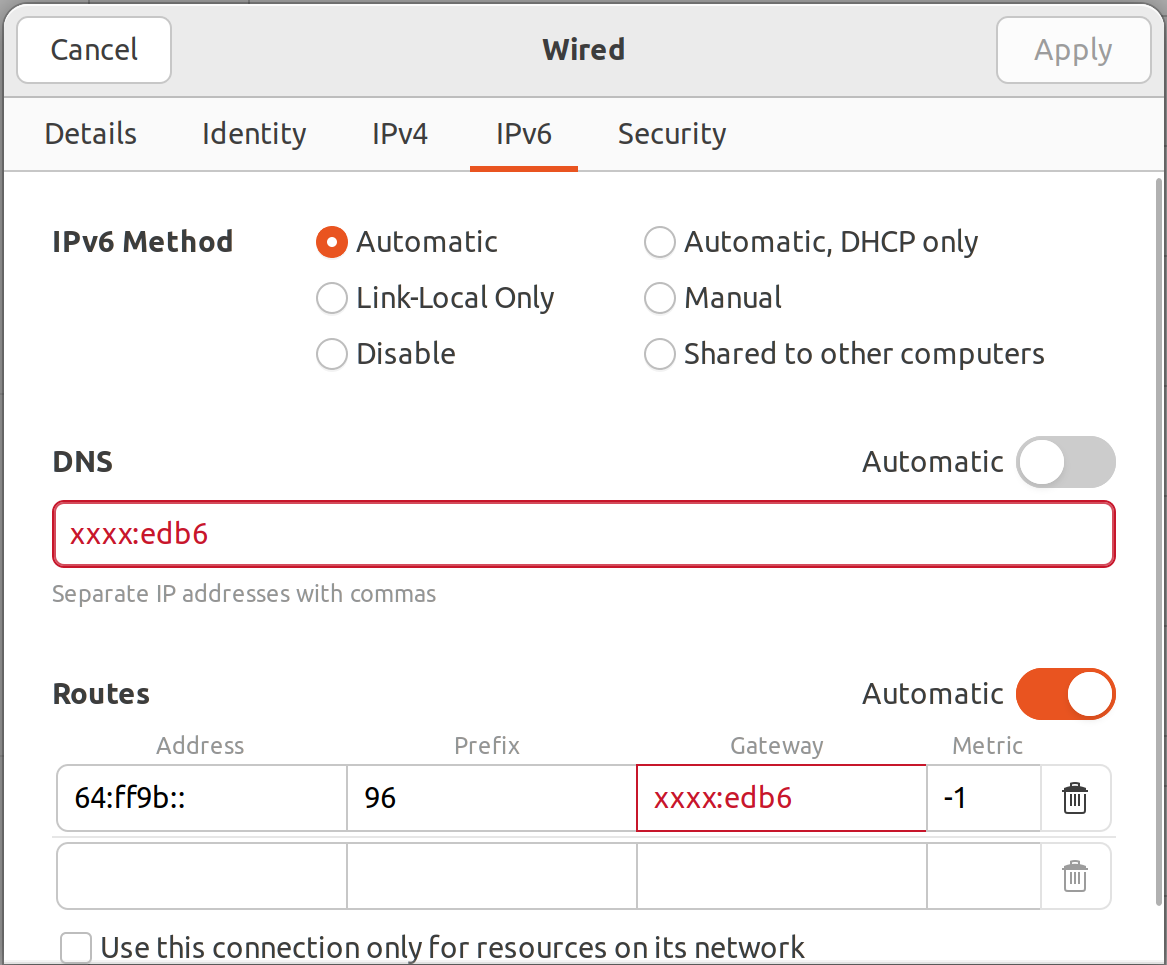
With such configuration radvd daemon will advertise that this prefix is accessible via machine's IPv6 address and all hosts in network will be able to use it.
You will need to replace end0 by name of your external interface of NAT64 box.
Then start it and enable autostart:
sudo systemctl enable radvd
sudo systemctl start radvd
Finally, reboot or disable / enable network on client machine.
To debug it from client I recommend installing this tool:
sudo apt install -y radvdump
Then you need to run application with same name:
radvdump
And after few seconds you will see banner like this:
interface enp37s0f0
{
AdvSendAdvert on;
# Note: {Min,Max}RtrAdvInterval cannot be obtained with radvdump
AdvManagedFlag off;
AdvOtherConfigFlag off;
AdvReachableTime 0;
AdvRetransTimer 0;
AdvCurHopLimit 64;
AdvDefaultLifetime 0;
AdvHomeAgentFlag off;
AdvDefaultPreference medium;
AdvSourceLLAddress on;
route 64:ff9b::/96
{
AdvRoutePreference medium;
AdvRouteLifetime 15;
}; # End of route definition
}; # End of interface definition
In same time your Linux routing table will receive following entry:
sudo ip -6 route|grep ff9
64:ff9b::/96 via fe80::8832:73ff:fe02:edb6 dev enp37s0f0 proto ra metric 100 pref medium
So we have nice network path towards our NAT64 prefix. That's very convenient and works just fine.
As final step I can recommend checking that some IPv4 host is accessible via IPv6 NAT64 prefix.
I've decided to try GitHub:
ping6 64:ff9b::140.82.121.3 -c 3
PING 64:ff9b::140.82.121.3(64:ff9b::8c52:7903) 56 data bytes
64 bytes from 64:ff9b::8c52:7903: icmp_seq=1 ttl=246 time=14.6 ms
64 bytes from 64:ff9b::8c52:7903: icmp_seq=2 ttl=246 time=14.1 ms
64 bytes from 64:ff9b::8c52:7903: icmp_seq=3 ttl=246 time=14.2 ms
--- 64:ff9b::140.82.121.3 ping statistics ---
3 packets transmitted, 3 received, 0% packet loss, time 2003ms
rtt min/avg/max/mdev = 14.145/14.305/14.574/0.190 ms
This approach highlights great deal of flexibility in IPv6 protocol as it was very easy to add new prefix for our own purposes inside of our own network.
I used following articles as basis for my research
one and
two.
In following release after 2.19 radvd will receive update which will make specific
statement for NAT64 prefix announcements.